Git and GitHub
This is the third module in the Building blocks topic.
Overview
Learning Objectives
Git is awesome … but it isn’t easy at first. We’ll look at how to use git and github in a data science workflow.
Video Lecture
Example
There are some important set-up steps before getting started. To follow along, you’ll need to have git installed and a GitHub account. You should make sure your GitHub username and email are established on your computer. You can do this in a terminal window, but I recommend running
usethis::use_git_config(user.name = "YOUR NAME", user.email = "your_GH_email")substituting your name and email. Help for git installation and troubleshooting can be found in Chapters 4-9 of this book by Jenny Bryan (note – all the rest of those chapters are also great).
For this example, I’m going to re-do work from Writing with Data.
New workflow – GitHub first
We talked about a good workflow in Writing with Data, with a focus on R Projects for organization and R Markdown for reproducibility. We’re adding version control using git to that workflow; git is useful by itself, and is also a popular tool to collaboration. There are a couple of ways include git in our workflow, but the one we’ll start with is:
- Create a GitHub repo with an informative name
- Create a linked R Project using File > New Project > Version Control
- Keep everything related to the analysis – data inputs, scripts, reports, output – in the directory, and use R Markdown as much as possible
- Keep track of changes using version control (save, commit, push)
- Periodically check for reproducibility of the analysis
The bold steps are new.
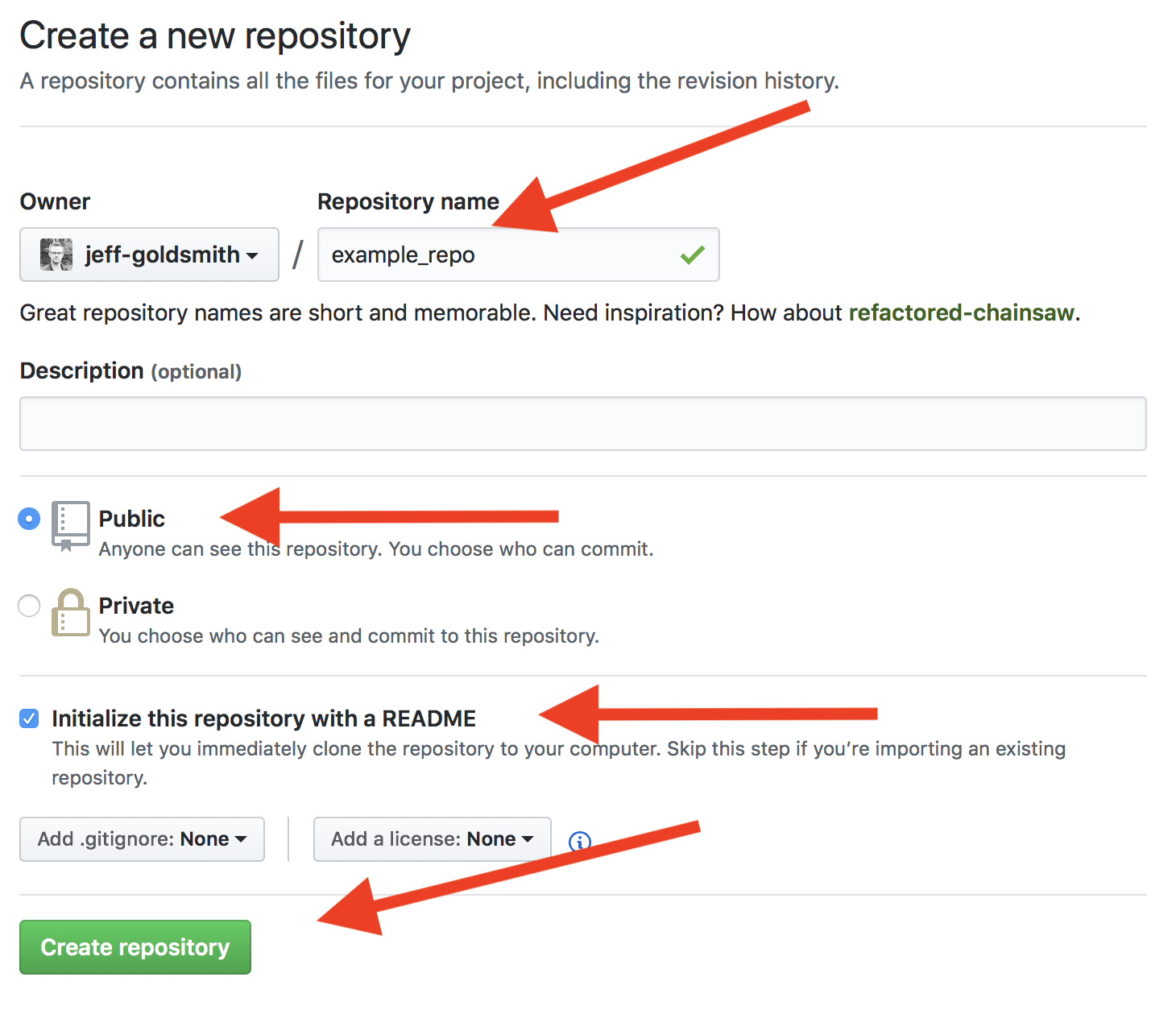
Walking through step-by-step, create a new GitHub repo online:

On the next page, choose your repo name, set to “Public”, initialize with a README, and create the repo
Once you have your GH repo, find the link to clone:
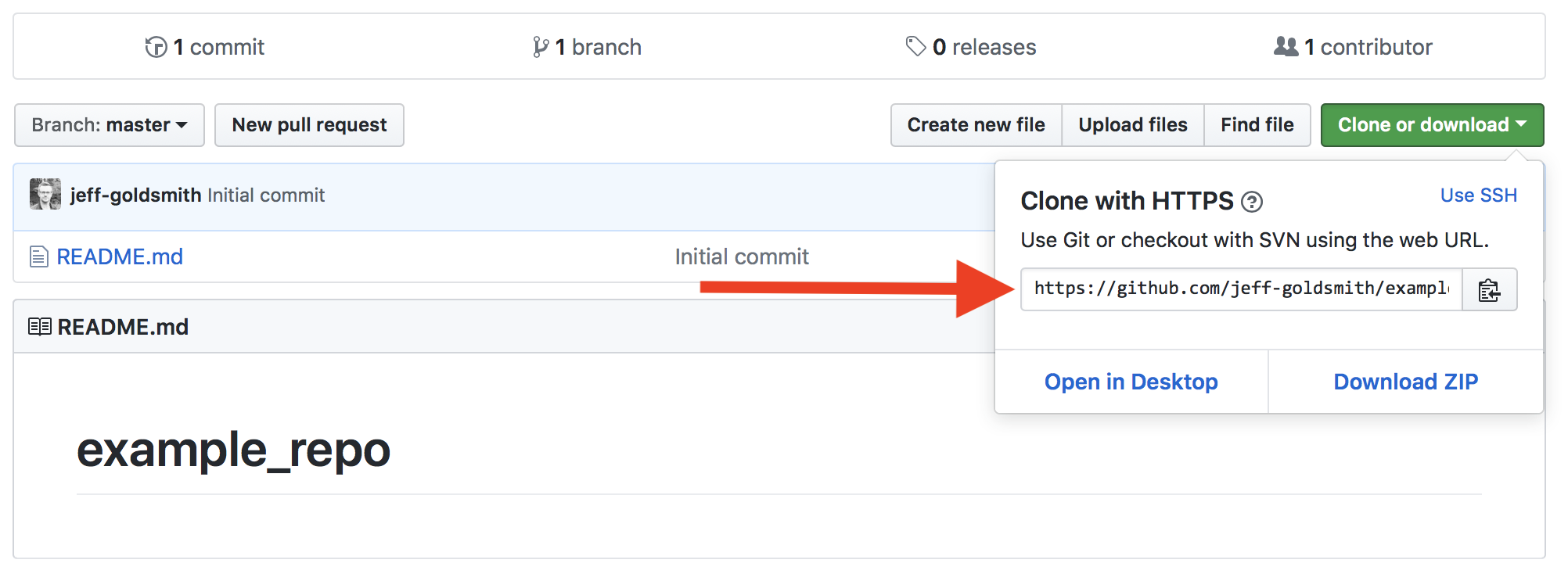
Now, in RStudio, start a new Project using File > New Project > Version Control.
- Provide the repository URL (copy from GitHub)
- Assign the Project a name (usually the same as the GH repo)
- Put the Project in a reasonable place on your computer
Once you’ve done this, a few things will happen. Most obviously, you
now have a Project with the name you chose, and that project contains
the .Rproj file, your README.md from GitHub, and a
.gitignore file (by default, this will ignore
.Rproj.user, .Rhistory, .RData,
and .Ruserdata). Less obviously, git is now watching your
directory and will keep track of changes across versions of your work,
and there’s a new “Git” tab in the top-right RStudio pane.
Learning Assessment: Follow the process above to create your own repo on GH and clone it as an R Project using RStudio.
Commit to git
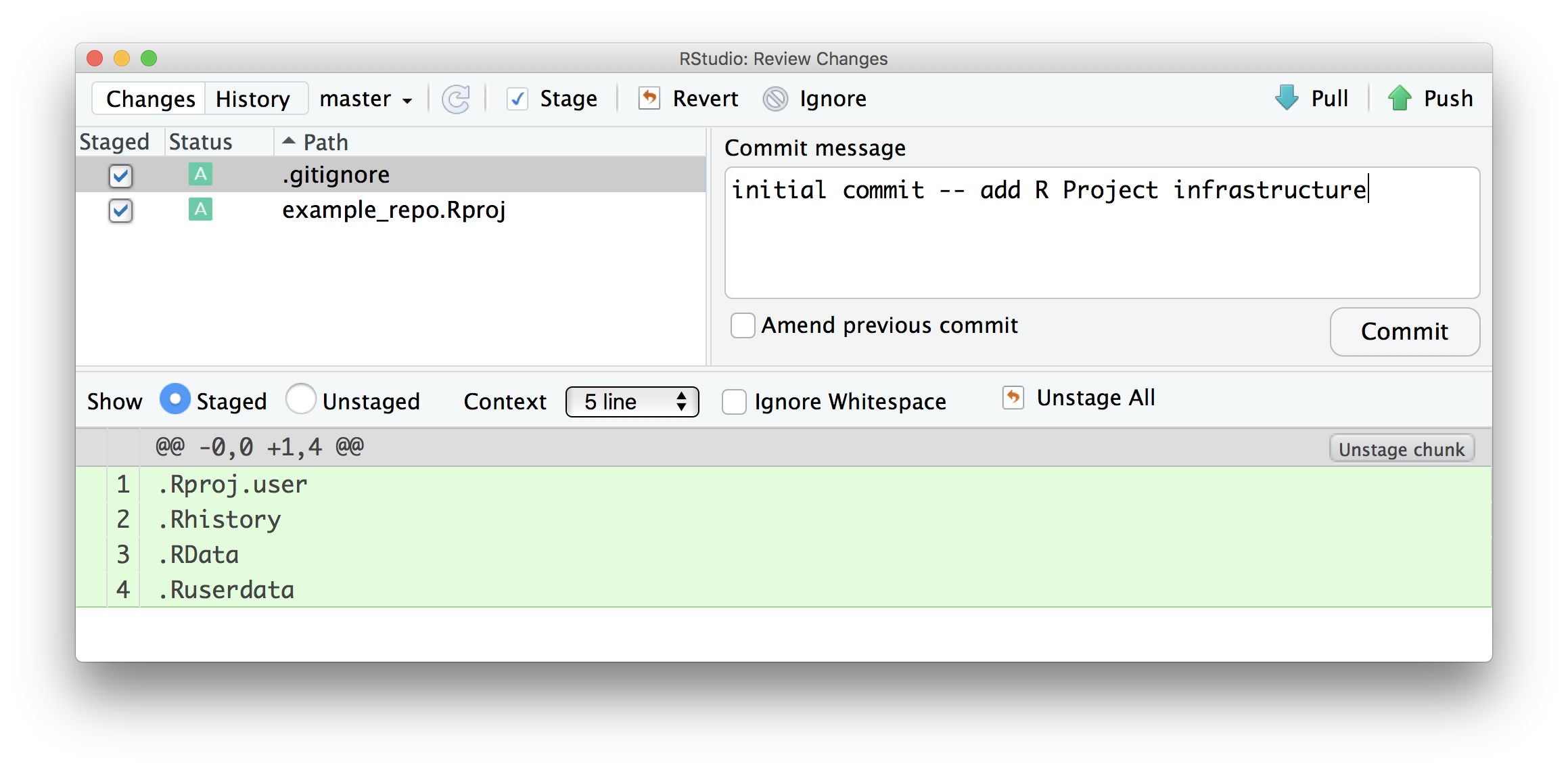
At this point, I haven’t done much “work” – I’ve created a repo and set up a project. Although I haven’t really done much yet I’m going to make an initial commit with the Project set-up, which is a nice starting point.
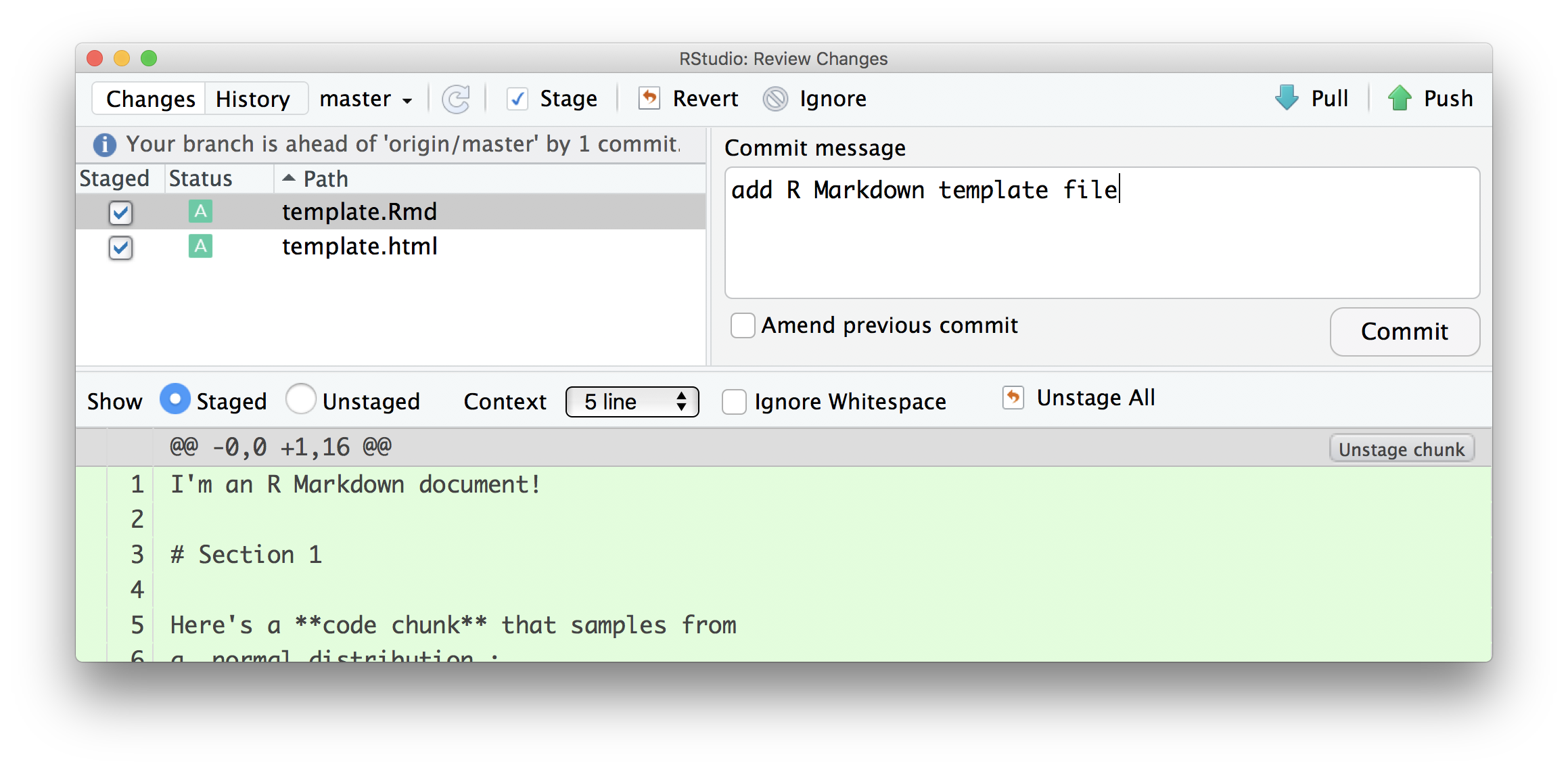
Now I’ll start actually doing stuff. As I noted above, I’m going to repeat some of Writing with Data – my goal is to focus on the git side of things without distractions from new code. As a first step, I’ll add an R Markdown template (download here), knit it, and commit.
Next I’ll add an R Markdown file looking at basic plots (shown below; download here) to my repository / directory.
---
title: "Basic Plots"
author: "Jeff Goldsmith"
date: 2024-09-10
output: html_document
---
```{r setup, include = FALSE}
library(tidyverse)
```
The purpose of this file is to present a couple of basic plots using `ggplot`.
First we create a dataframe containing variables for our plots.
```{r df_create}
set.seed(1234)
plot_df = tibble(
x = rnorm(1000, sd = .5),
y = 1 + 2 * x + rnorm(1000)
)
```
First we show a histogram of the `x` variable.
```{r x_hist}
ggplot(plot_df, aes(x = x)) +
geom_histogram()
```
Next we show a scatterplot of `y` vs `x`.
```{r yx_scatter}
ggplot(plot_df, aes(x = x, y = y)) +
geom_point()
```Now I’ll commit.
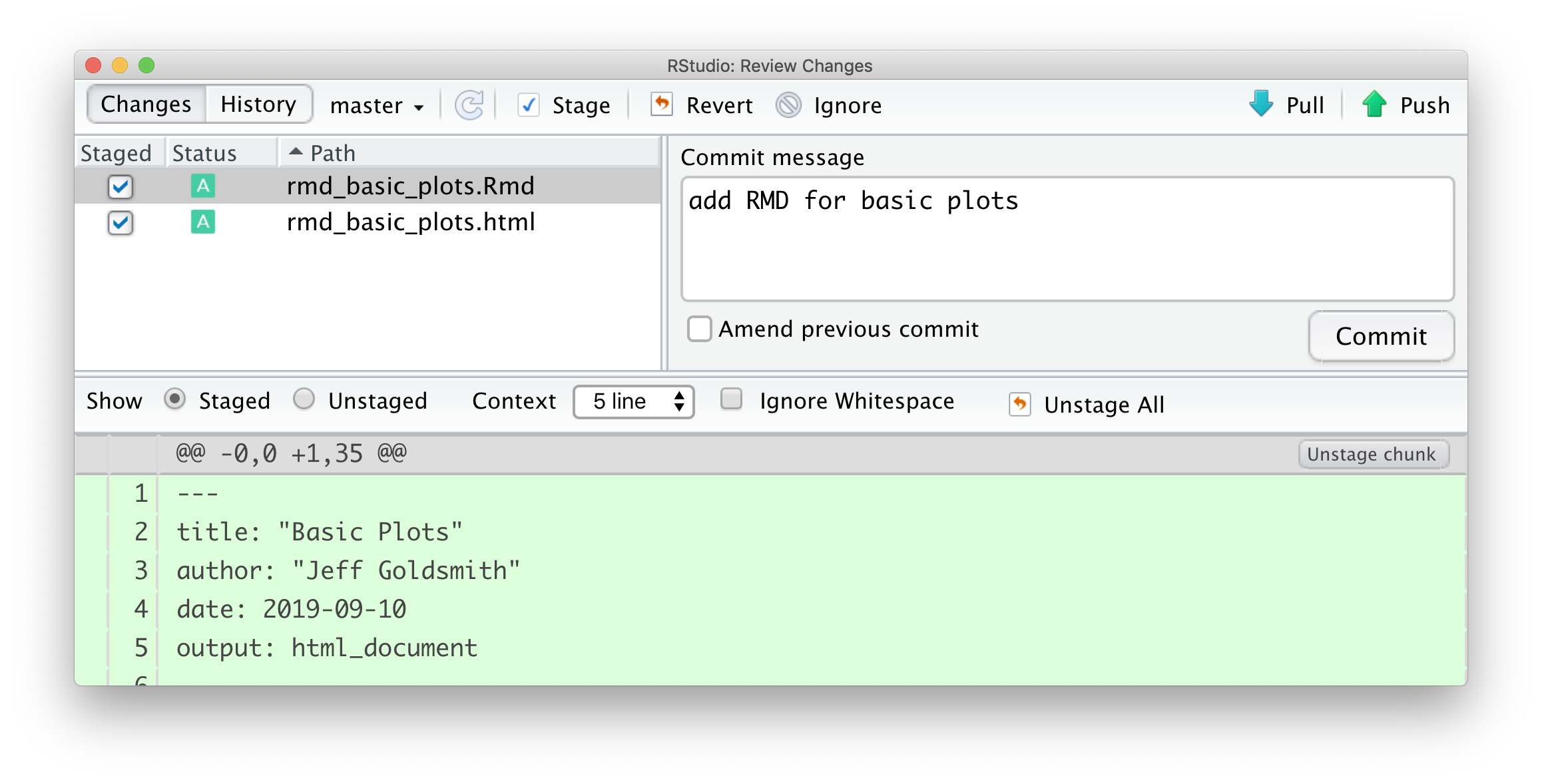
Next I’ll update my README.md file. And commit.
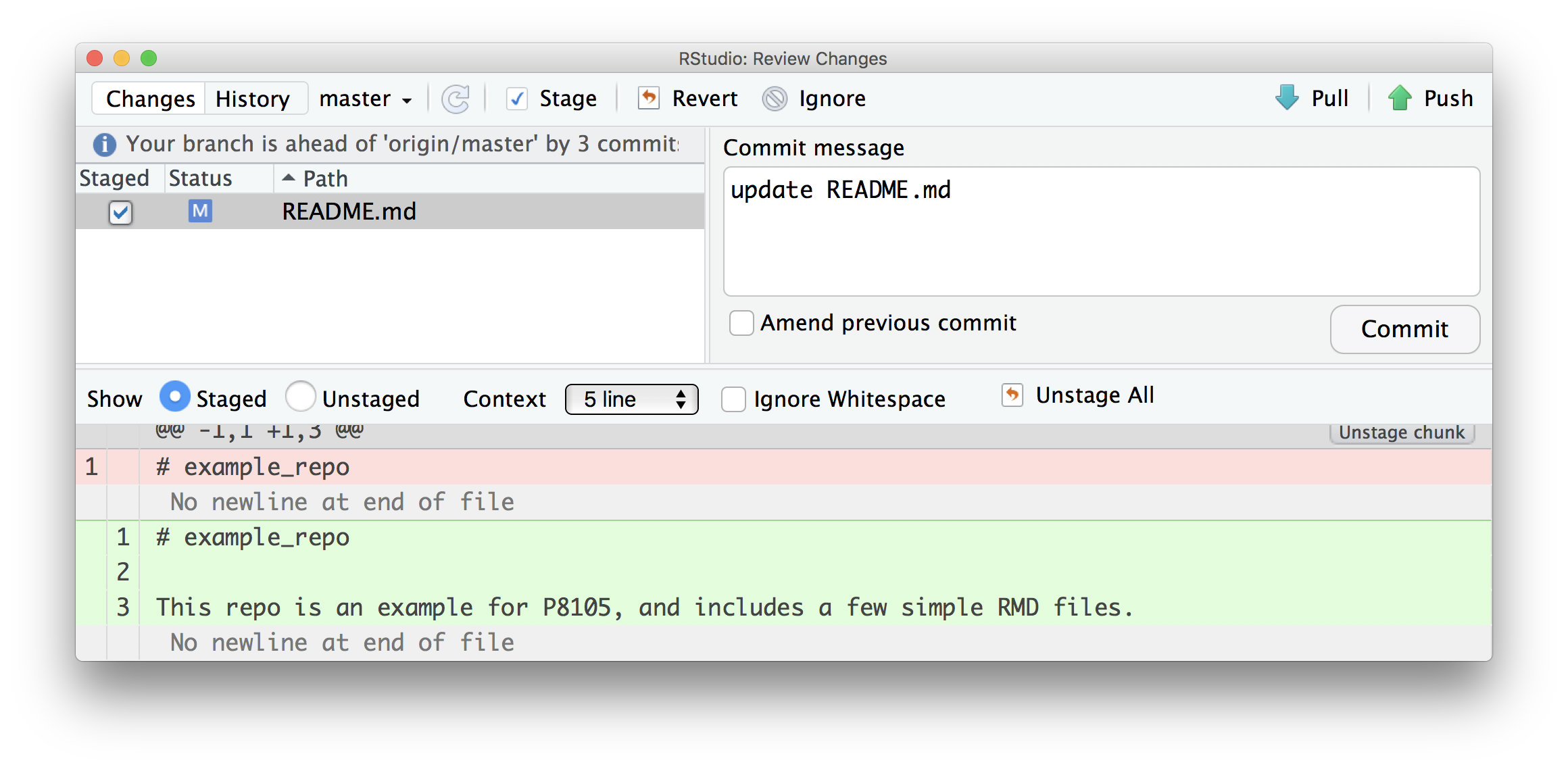
How frequently you commit is, to some extent, a matter of taste. Roughly speaking, I commit after changes that are big enough to that I’d want a reminder about what they contain in six months. Also, after a while, committing becomes almost second-nature (or at least isn’t something that takes a lot of time or energy) and that makes it easier to commit often.
The commit messages and git diffs are key features, and will help you understand (or remember) what changed at each stage – commit messages should summarize main changes (and maybe give some details), and git diffs will show what files were added / edited and what the line-by-line changes were.
Learning Assessment: Make some changes to your repo (edit your README, add a file, etc) and commit those changes.
Pushing to GitHub
Git is useful as a version control system all by itself, but it is especially powerful when combined with GitHub. This combination relies on pairing your “local repository” with a “remote repository” – local is on your computer, remote is in the cloud (i.e. on GitHub’s servers). Fortunately, in the “GitHub First” workflow, the local / remote pairing is basically done for you. However: you still have to make sure that GitHub and RStudio are configured to talk to each other. This process can be confusing and stressful, even for git veterans, but usually only has to be completed once and there are useful R packages that make this easier.
A key step is the creation of a Personal Access Token. As always, there are several ways to do this, but I recommend you use
usethis::create_github_token()This will take you to GitHub, where you’ll establish scopes (recommended scopes “repo”, “user”, and “workflow” will be selected by default), name your token (mine is “GH_Macbook”), and say how long this token will last. Copy your token or keep this page open. Once you’ve set up your PAT and try to push, RStudio may prompt you for your GitHub username and password; provide your new PAT, and you’re be all set. Alternatively, run
gitcreds::gitcreds_set()and you’ll be prompted to input your PAT.
Once you’ve done all this, the next step is to “push to remote”, a step that drives home the difference between local and remote repositories: you can make local changes and commits, but the remote repository won’t know about them until you push.

Once you’ve pushed, all your commits are viewable on GitHub.
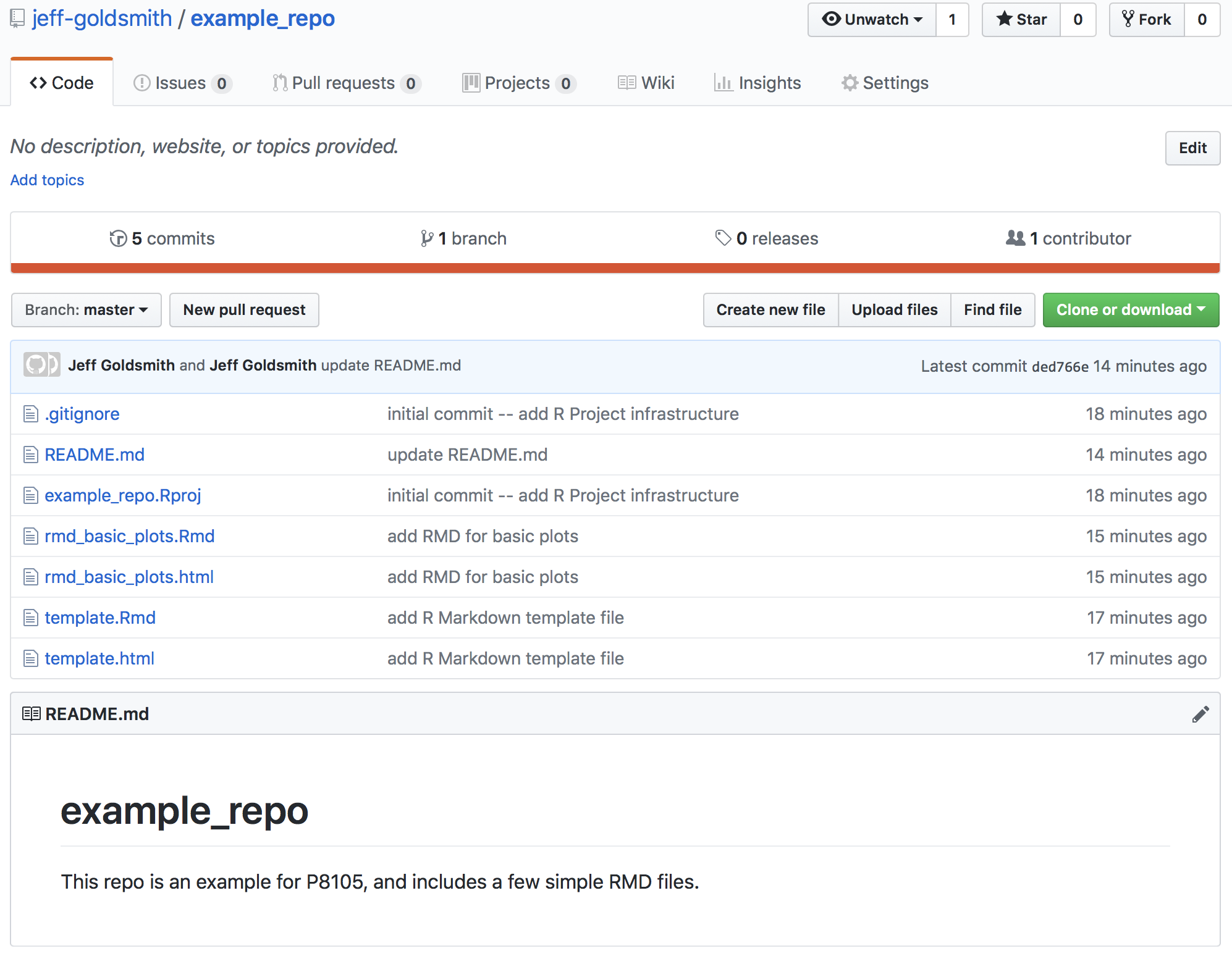
GitHub has a lot of features that help as projects grow: issue trackers function as collaborative “to-do” lists, the built-in message system helps coordinate with collaborators, and others. You can also see what other people are working on, follow repos or developers, create your own versions of existing repos, and do other exciting stuff!
Learning Assessment: Make sure you can push your commits to remote!
.md Files on GitHub
Markdown files (not R Markdown, just .md files) are rendered in an HTML-like way on GitHub. We already took advantage of this, in fact, in the README.md file – this has particular prominence on a repo’s GH page, but other .md files are rendered similarly.
Our use of R Markdown to write reproducible reports makes the
treatment of .md files on GH especially nice. Recall that we used
knitr::knit to render a .Rmd file to a .md file, which in
turn was rendered to another format (.html, .pdf, .docx). By using the
github_document output format, we can instead produce .md
files (there are, of course, other ways to achieve the same end). This
is great, because the report – including text, code results, and figures
– can be produced in a way that is easily viewable on GitHub!
Learning Assessment: Change one (or both)
of your .Rmd files to output github_documents. Re-knit,
commit, and push – and then view the results on GitHub.
Collaborating via GitHub
Sharing repositories via GitHub makes it possible to collaborate in a clear, rigorous way. As each person makes changes:
- written commit messages let others know what has changed and why
- line-by-line comparisons (additions and deletions) show exactly what was changed.
This is great if you’re working in a team, or if you are considering future-you as a collaborator.
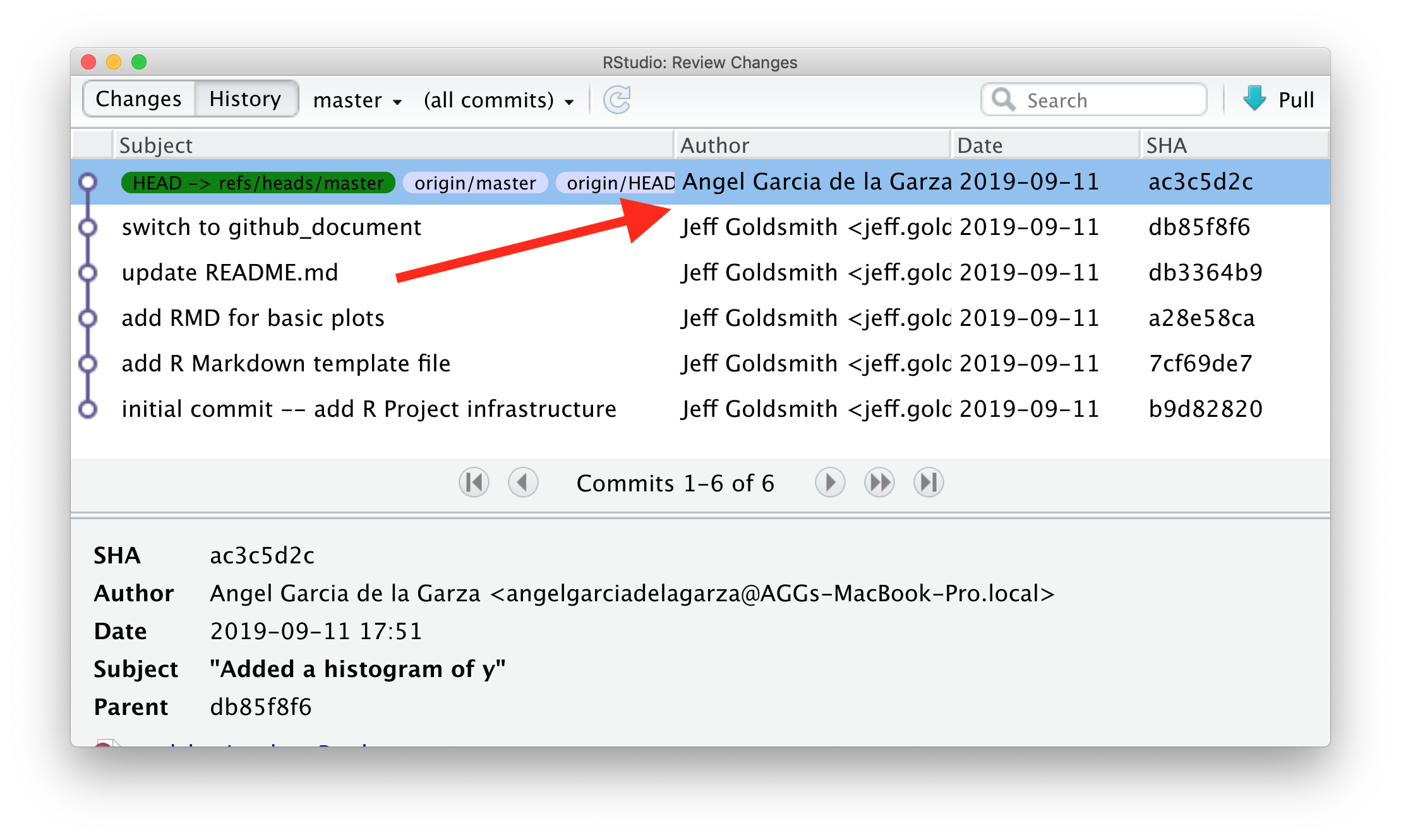
For the repository holding this example, I’ll add Angel as a
collaborator. Once he’s been added, he’s going to add a histogram of
y to our basic plot RMD. He’ll commit and push; I’ll relax
until he’s done, then pull his changes from the remote repository to my
local repository. Those changes will appear in my local repository, and
a summary of the changes are in my git history.
Of course, team members may want to work in parallel. As an example, I’ll edit the README a bit and Angel will edit the template RMD file. Once I’ve written my code, I’m going to commit; pull to see if there are any changes in the remote repository; and then push everything.
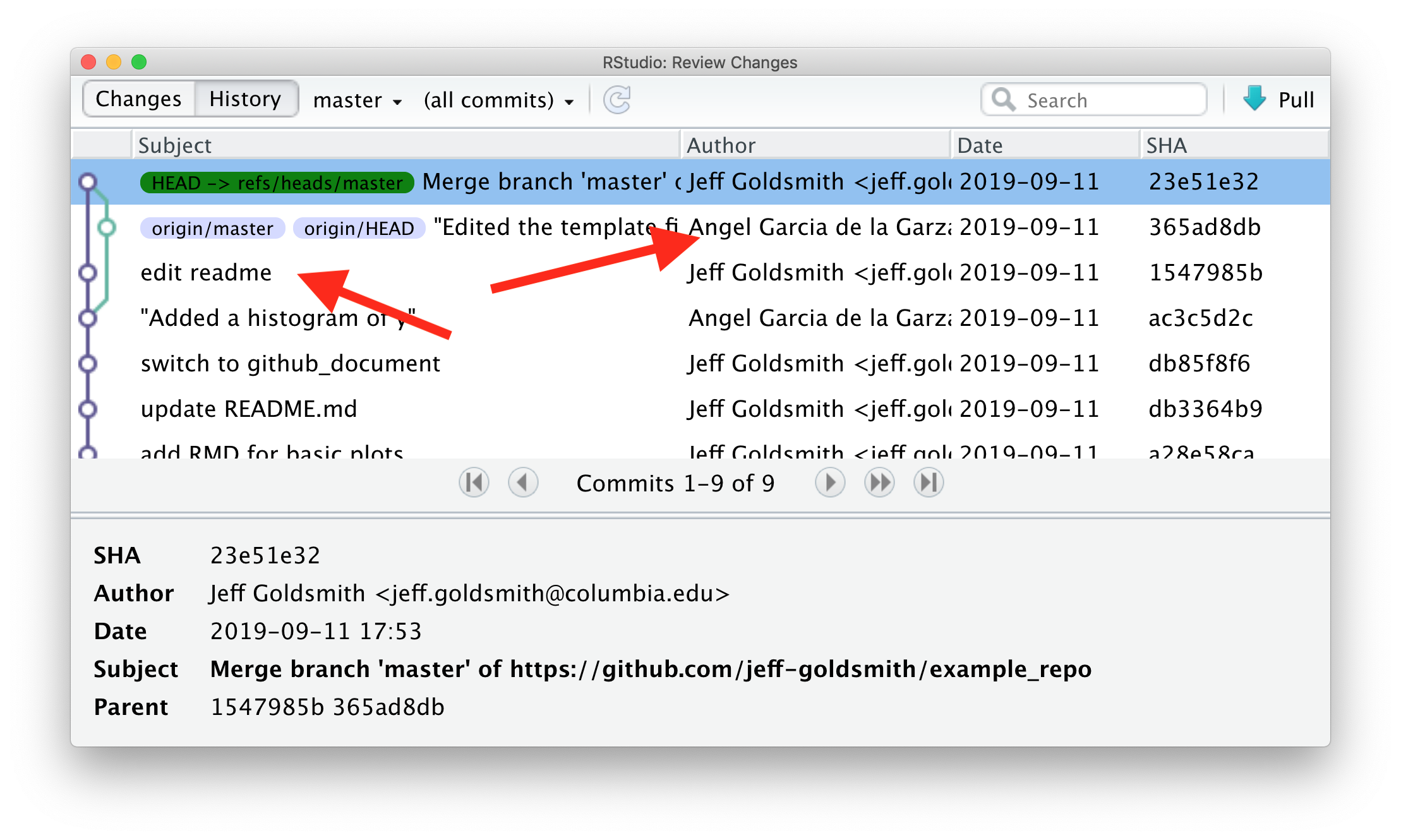
This process (commit > pull > push) can help keep you out of trouble, although other approaches are possible.
Conflicts
When we’re working in parallel on non-overlapping elements, everything is pretty smooth. I can edit and commit, and so can Angel; as we cycle through the commit > pull > push cycle, git knows we’re not editing the same stuff and keeps track of the changes.
We can run into issues when we both edit the same thing – suppose,
for example, we both try to update the line describing the purpose of
basic_plots.Rmd. If he commits and pushes before I do, when
I commit and pull I’ll see the following:
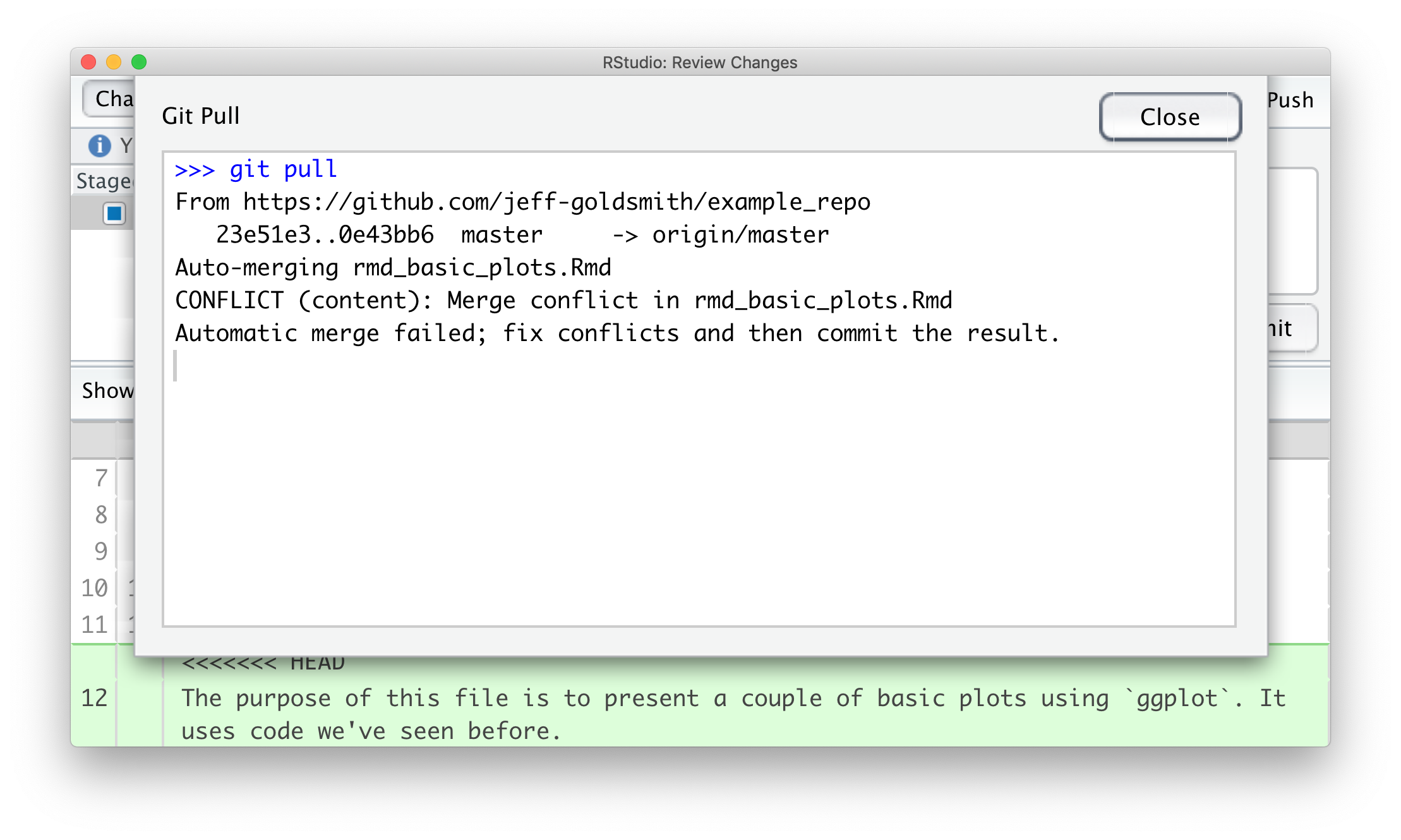
We’ve both written text in the same place, and have to make a decision about which to keep. You have a couple of options: one is to open the file in question, go through each conflict (which will be indicated in text), fix the text to your liking and remove all the markers that indicate the conflicts. We can also do this with the help of a merge tool, which will show where differences are and allow us to make a choice about which to keep.
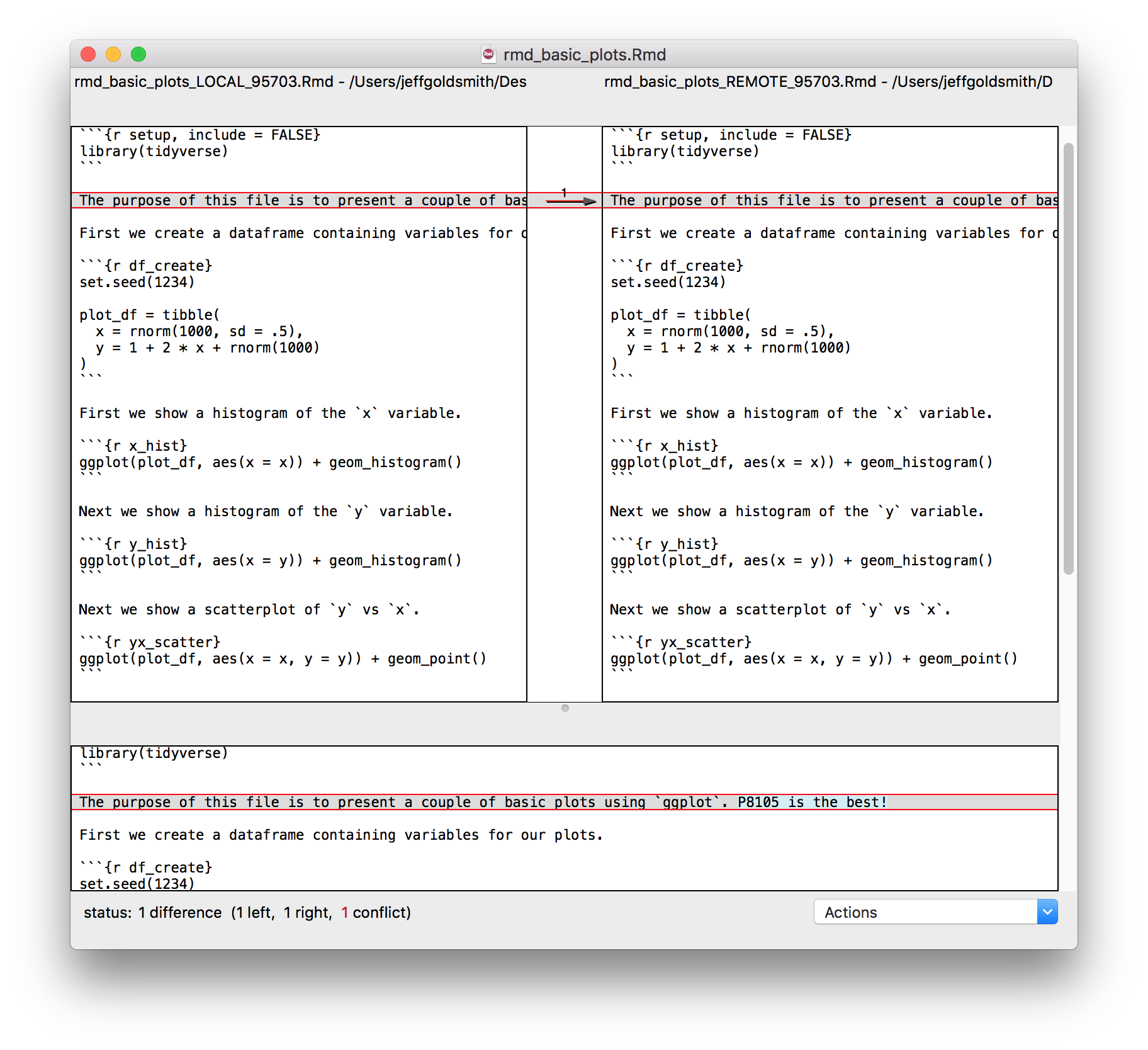
After resolving conflicts, I should commit the changes and push the new unified version to the remote repository.
Merge conflicts are a fact of life in collaborative work, and you probably run into them more often than you’d like to admit (e.g. “Jeff’s Conflicted Copy” in Dropbox, or parallel versions of Word documents). Git can seem like it makes this worse, but that’s mostly because it’s new and scary, and it forces you to address conflicts as they arise in a structured way rather than ignoring issues / managing them in an ad-hoc way.
That said, try to coordinate with teammates so it’s clear who is working on what and when they’re doing it.
Alternative workflow – Project first
The “GitHub first” workflow works well, but it’s not the only way to add version control to an R Project. An alternative is “Project first”:
- Create an R Project with a reasonable name and path (via
usethis::create_project()) - Turn on version control for the project using git
(via
usethis::use_git()) - Optionally, create remote repository (via
usethis::use_github()) - Keep everything related to the analysis – data inputs, scripts, reports, output – in the directory, and use R Markdown as much as possible
- Keep track of changes using version control (save, commit, push)
- Periodically check for reproducibility of the analysis
Bold steps are new with respect to the workflow in Writing with Data. This workflow is useful if you don’t intend for your repo to end up “in the cloud”, which his sometimes the case, but means you have to take steps to create the remote repository.
Other materials
There’s a lot of stuff to help with git in general, and with git for R in particular. This is a non-exhaustive list:
- Jenny Bryan’s article “Excuse me, do you have a moment to talk about version control?” is excellent
- Jenny Bryan’s book (same as the link above) is really helpful, and has chapters on several workflows
- The GitHub guide
- Version control with RStudio
The GitHub repository I created working through this example is here.